
Performance Estimation - Pt. 1
An overview of tools and methods to estimate performance of your ML model

Once your model is deployed, monitoring its performance plays a crucial role in ensuring the quality of your ML system. To calculate metrics such as accuracy, precision, recall, or f1-score, labels are required. However, in many cases, labels can be unavailable, partially available or come in a delayed fashion. In those cases, the ability to estimate the model’s performance can be helpful.
In this post, I want to discuss possible methods for estimating performance without ground-truth data. While this post does not provide any code, I plan to provide examples in Jupyter Notebook format for each approach in future posts.
NannyML
NannyML is a Python package for detecting silent model failures, estimating post-deployment performance without labeled data, and detecting data drift. Currently, NannyML has two methods for performance estimation: Confidence-based Performance Estimation (CBPE) and Direct Loss Estimation (DLE). For a more detailed description of these methods, please refer to the NannyML original documentation.
a. Confidence-based Performance Estimation
Much like the name suggests, this method leverages the confidence scores of the model’s predictions to perform performance estimation.
Considerations: There are some requirements and assumptions to be aware of when using this method.
Confidence as probabilities: the confidence scores should represent probabilities - e.g. if the score is 0.9 for a large set of observations, it would be correct approximately 90% of the time.
Well-calibrated probabilities: another requirement is that the scores should be well-calibrated, which might not always be the case. The good news is that NannyML performs calibration internally if needed.
No covariate shift to previously unseen regions in space: if your model was trained on people with age 10-70, and in production, your observations are of people over 70, this approach will likely not provide reliable estimations
No concept drift: if the relationship between the inputs and targets of your model changes, this approach will likely not provide reliable estimations (I personally don’t know any approach that would)
Poorly fit for regression models: regression models often don’t inherently output confidence scores, only the actual predictions, which makes the use of this method non-trivial for such cases.b. Direct Loss Estimation
b. Direct Loss Estimation
The intuition behind this method is to train an extra ML model whose task is to estimate the loss of the monitored model. The extra model is called the Nanny Model, and the monitored model is the Child Model.
Considerations:
Extra model: it is required to train an extra model to estimate the losses of the original model, which increases the complexity of your system. However, the model doesn’t have to be better than the original model, and in many cases, it can be a straightforward process.
Fit for regression: this approach is well-suited for regression tasks. The nanny model can be trained to predict MSE (Mean Squared Error) or MAE (Mean Absolute Error), for instance.
No covariate shift to previously unseen regions in space: the same considerations made for CBPE applies to this method as well
No concept drift: the same considerations made for CBPE applies to this method as well
Regions with different performances: the monitored model should have varying performances across different regions. For example, if your model performs better or worse according to different periods of the day different seasons.
Importance Weighting
I first knew about this approach by attending an O’Reilly Course called Monitor Real-Time Machine Learning Performance by Shreya Shankar. The intuition is that you can leverage a reference dataset for which you do have labels to estimate the performance of an unlabeled target dataset. This can be a dataset you used in a pre-deployment stage, such as the test split from when you originally trained your model. To do so, we first define segments with well-defined criteria, and then calculate the performance, let’s say accuracy, for each segment of data. This could be, for example, segmenting according to the age, profession, or product category. To estimate the accuracy of your target dataset, you then apply the same rules to segment your data, and weight the original reference segmented accuracies with respect to the target dataset’s segment proportions.
I really like this approach because the intuition is very clear and the implementation is straightforward.
We are considering here that the main reason for the difference in performance between the reference and target datasets is due to a change in the distribution of the input data. This is known as covariate shift.
Considerations:
No concept drift: if the relationship between the inputs and targets of your model changes, this approach will likely not provide reliable estimations. Again - I don’t know any approach that would
Covariate shift to unknown regions of the feature space: Suppose our model was trained with a demographic of age 15-70. If during production we receive data from a demographic with age 0-14 or above 70, the model's performance will likely decrease, and it is possible that this approach will not yield accurate estimates
Importance of segmentation: Choosing the proper way to segment your data is very important. The segments in the target dataset must be a subset of the reference dataset, as an unseen segment will not have an associated accuracy. The segments also should ideally have high variance in training accuracies: if all segments have the same accuracy, then weighting them would not make much sense. You should also be able to perform the segmentation during production easily, without having to manually label them - that’s what we’re trying to get away from the start!
Mutually exclusive and exhaustive segments: To the best of my knowledge, this approach works only with mutually exclusive and exhaustive segments. That means that our segments don't overlap with each other, and the sum of the segments equal to the complete dataset.
Mandoline
Mandoline is a framework for evaluating ML models that leverages a labeled reference dataset and the user’s prior knowledge to estimate the performance of an unlabeled dataset. The key insight here is that the users can leverage their understanding to create “slicing functions” that capture the axes by which the distributions may have changed. These functions can group the data either programatically or by using metadata.
There are similarities with the approach presented in the previous session, considering that both use a similar concept of buckets/slices/segments, and both use these groups to reweight the source data. In Mandoline, the slices created will help guide a following density estimation process, and these estimates are then used to reweight the source dataset and output a performance estimate.
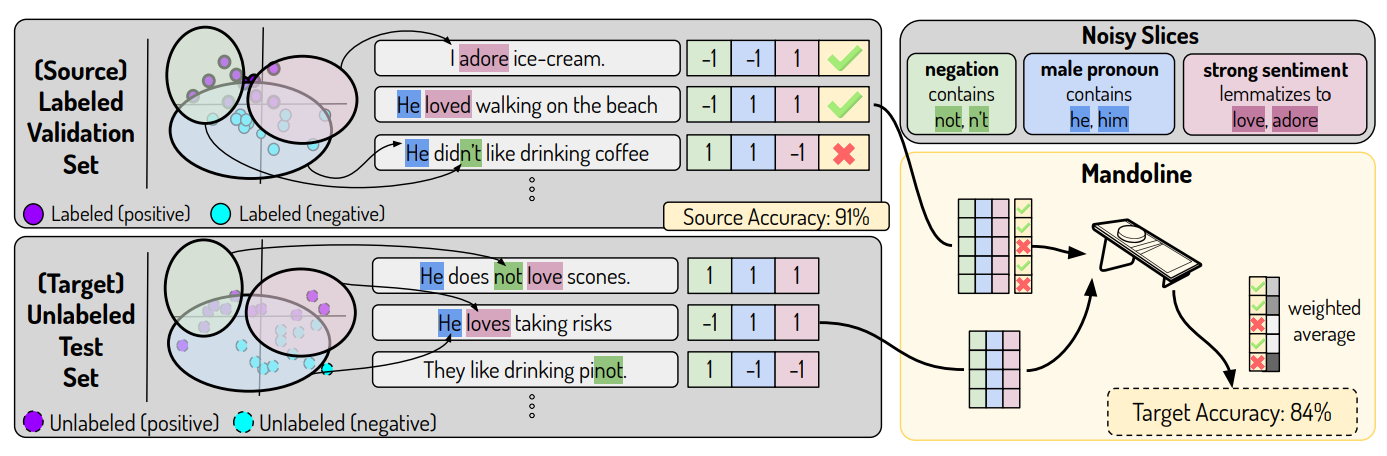
The paper is very interesting and well worth reading, and it looks like the results are very promising. They also provide a python implementation of the framework, which I plan to explore in future posts.
Considerations
No concept drift: Again, the problem formulation assumes that there is no concept drift between the distributions.
Works with noisy, underspecified slices: This approach works well even if your slices are noisy and/or underspecified. Let’s take one example present in the paper - detecting toxicity with the CivilComments dataset, and you want to segment based on demographics, such as male, female, christian, LGBTQ, etc. You can use regex functions that looks for keywords, such as “man, male, female” to group your data. This will not get the slices right 100% of the times, but even so the approach performs well. Also, to the best of my knowledge, this approach works with overlapping segments - each comment can mention one or more demographic.
Importance of slicing: Properly designing your slicing functions is critical. They should be relevant to the task at hand, and should effectively capture different axes of possible shift in your distributions.
Future Experiments
In future posts, I plan to experiment with each approach in practical use cases. The goal is not to compare the performance of each approach, but simply show how we can use those approaches in a practical scenario. Since each approach has different sets of requirements, it is likely that we’ll use different datasets and use cases for each approach. For example, Mandoline supports the use of overlapping segment. In the other hand, the Importance Weighting approach works with mutually exclusive and exhaustive bins. Both the CBPE and DLE approaches don’t assume segmentation of any kind, but we do need to have a model with confidence scores that are well calibrated (CBPE) or train an extra model (DLE).
Thanks for reading! I hope you stick around for the next posts!
References
Chen, Mayee, et al. "Mandoline: Model evaluation under distribution shift." International Conference on Machine Learning. PMLR, 2021. https://arxiv.org/abs/2107.00643
Shankar, Shreya, and Aditya Parameswaran. "Towards Observability for Production Machine Learning Pipelines." arXiv preprint arXiv:2108.13557 (2021).
ML Monitoring Tutorial - https://github.com/shreyashankar/oreilly-monitoring
NannyML - https://www.nannyml.com/
Estimation of Performance of the Monitored Model - https://nannyml.readthedocs.io/en/stable/how_it_works/performance_estimation.html#
Great read! It seems like Mandoline is an absolute improvement on top of Importance Weighting, albeit more complicated. Are there scenarios where Importance Weighting might work better?